Introduction
Small Time?
Ive been using TimescaleDB as part of the back-end for Old School Snitch, a plugin for the game Old School Runescape that tracks individual XP gains and item drops, as well as your in-game location, for roughly 100 users. Old School Snitch is a hobby project of mine, I live with downtime during updates, I have no HA strategy, and the database size is still under one gigabyte total. This post is a collection of my thoughts and experience developing with Timescale under those moderate conditions.
The Data of Old School Snitch
Old School Snitch collects small, event-driven bursts of data, inserted into Timescale one at a time as they are received.
There are 4 types of data that Old School Snitch tracks:
- XP Gains
- NPC Kills
- Item Drops
- Player Locations
Each of these gets their own table. And the structure follows a pattern of timestamp, player_id, then 3-4 columns of the relevant data.
You can see how my player's data is displayed here. Importantly, the most granular display of the data (outside of locations) is shown at an hourly level.
How I Use Timescale
What is TimescaleDB?
TimescaleDB (henceforth referred to as Timescale) is a Postgres extension that provides a set of tools to efficiently store and query time-series data in the database and expose that data as regular tables. These special tables are referred to as hypertables and all four of the Old School Snitch data types are stored in hypertables. The Timescale features I get the most benefit from are the data compression and continuous aggregates for those hypertables.
Compression
On their website, Timescale claims between 80% - 95% compression when its enabled for their hypertables. I've always been quite skeptical of this, but I have been pleasantly surprised to see 90+ percent compression when it comes to my own data.
| Table Name |
Before Compression | After Compression | Percentage Reduction |
|---|---|---|---|
| xp_drops | 495 MB | 15 MB | 97% |
| item_drops | 65 MB |
5 MB | 92% |
| npc_kills | 12 MB | 0.7 MB | 94% |
| locations | 3714 MB | 246 MB | 93% |
In previous versions of the extension you were unable to modify the data after compression, but updates to Timescale have made it possible to run updates/deletes, as well as modify the table schema. So with minimal downside you get some incredible compression. Timescale also supports automatic data retention policies to remove data after a certain amount of time. I'm taking advantage of these automatically delete any data older than 30 days from these tables.
Continuous Aggregates
I'll let you in on a secret: Old School Snitch does not keep individual item/xp drops long-term, they get rolled up into hourly sums and those are used for long term storage. Not the most difficult task to accomplish yourself, but Timescale provides the Continuous Aggregates (CAs) feature to do it all automatically. CAs let me take the xp_drops table, and create an xp_drops_hourly materialized view that contains the hourly sums of any xp gained, broken down by player and skill so the data remains usable for display.
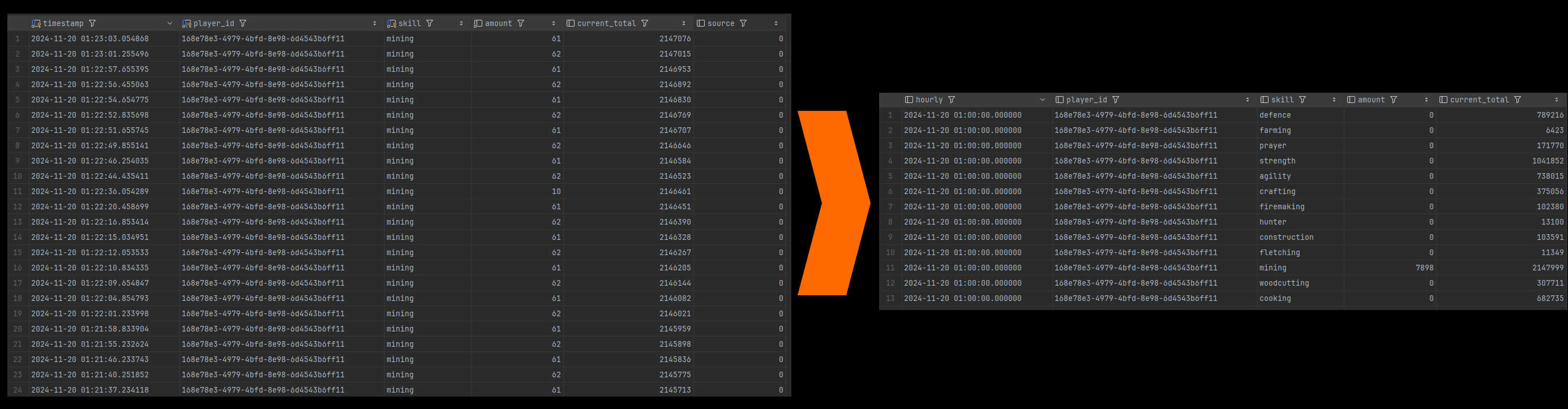
I only ever have to query xp_drops_hourly for displaying the data on a player's page. Timescale handles automatically updating the view, as well as aggregating the latest data from the base table and including that data in the results when the view is queried.
CA's have refresh policies, which let you define the boundaries on which data gets aggregated into the view. The xp_drops table automatically drops data that is greater than one month old. By setting the start/end offsets on the policy to not go older than one month, the view does not remove the deleted data (the docs for this process are available here). Timescale keeps the historical aggregated data in the materialized views, leading to even greater space savings than just compressing the base xp_drops table.
However, this approach does come with a major pain point: altering any data requires disabling compression and the refresh policies, copying the data out of the view into the base table, then modifying the data and re-creating the continuous aggregate. After seeing how good the compression ratios are, it is quite tempting to just disable the retention policies and keep the data in the base table forever. I would still use the CA's to simplify querying the data for viewing.
The Developer Experience
Since Timescale is a Postgres extension, I do not need any additional tooling to use it. No new query language, I use my normal ORM to handle queries and migrations, and I can seamlessly join my time-series data against my normal data with no extra hoops. Frankly, I don't have much more to say about that. Its SQL, it works well with all of the tooling I use for SQL.
If you use a testing framework that creates new test databases every run, make sure that you keep the version of timescale in TEMPLATE1 in sync. Chances are your migration has a variant of "CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE" which won't account for updating the extension if it already exists in TEMPLATE1.
The Timescale documentation is generally well written, but they do not separate the docs for the extension from their hosted service. This is annoying when looking for the admin-related documentation such as backups/replication for a self-hosted instance.
Deployment & Administration
Using Timescale also simplifies deployment, since you don't need to worry about deploying another service. In both Dev and Prod environments I use the official Docker container. This has been convenient and has worked fine for me, but is not what I would recommend in proper production environments.
With the docker container, upgrading to the next Postgres major version is going to be a major pain. pg_upgrade requires having both versions of the Postgres executable to run the upgrade. This will require building up a custom docker image to accomplish.
Logical replication is not recommended (read: not supported) in Timescale. This means your Failover and/or Read replicas must all be on the same version since you can only use streaming replication. With logical replication not supported, an upgrade is going to involve a full pg_dump and pg_restore alongside downtime.
If you are going to use their docker container, be very specific with the container version you pin to. It only happened once previously, but a newer version of the container got uploaded that was totally unable to boot Postgres. Don't just pin it to pg-15-latest for example.
Timescale does use a custom license restricting others from providing paid hosting of the version with the good features (most importantly: compression). I self-host Timescale on a dedicated server, but if you are an Azure/AWS only shop, you won't get all of the features without either using Timescale's official hosting or handle hosting it yourself.
Conclusion
Timescale has been an absolute joy to develop with. Having all of my data within the same database makes development a whole lot easier than if I had to join two sets of data at the service level. Compression and Continuous Aggregates are key to keeping the storage space tiny compared to what I expected. The only major pain point I have experienced is the lack of support for logical replication.
After my current Postgres version reaches EOL, I'll probably bite the bullet and switch from the docker container to a bare-metal install of Postgres to simplify future Postgres upgrades.
Feel free to reach out to me on the Fediverse if you have any questions or comments!
179.8k mining xp was gained during the composition of this post.